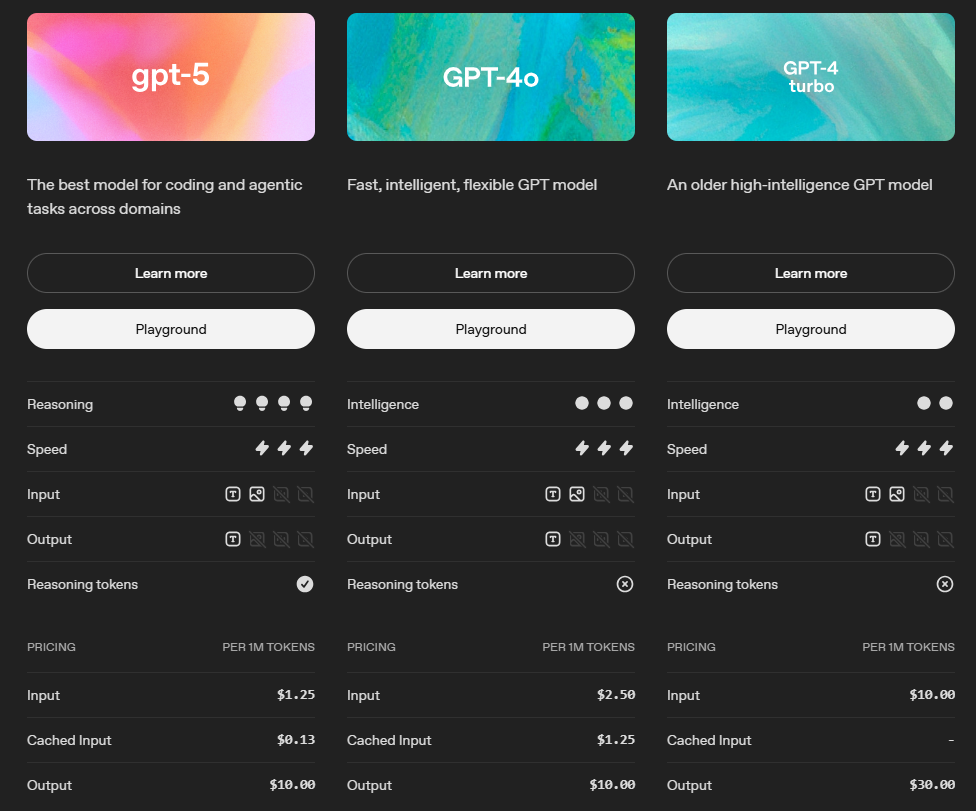
In this article, we will set out some examples of how many tokens are used by Modeller AI across its various use cases. There are a number of different LLMs available on the market at different price points, so in this article we will only calculate the number of tokens used. To calculate indicative pricing, please use the costing provided by your LLM provider, here are some examples from OpenAI.
Models:
| Feature | Specifics | Estimated Tokens Used |
|---|---|---|
| IntelliAgent | Single request, small/medium sized model | 650 tokens (300 input, 350 output) |
| IntelliAgent | Single request, large model | 1000 tokens (650 input, 350 output) |
| Wireframe Image -> Model | One image | 500 tokens (250 Input, 250 Output) |
| Text/User Story -> Model | 100 words | 400 tokens (200 input, 200 output) |
| Requirements Document -> Model | 10,000 words, 20 images | 19,000 tokens (14,000 input, 5,000 output) |
| Requirements Document -> Model | 850 words, no images | 2,000 tokens (1,400 input, 600 output) |
| Requirements Document -> Model | 5,000 words, 2 images | 9,000 tokens (8,000 input, 1,000 output) |
| Model -> User Story | medium sized model | 500 tokens (300 input, 200 output) |
***these are indicative token usage statistics and not an exact science - real usage figures will vary depending on exact inputs/outputs***