Enterprise Test Data
Data insights and dashboards
The Data Insights dashboard provides an overview of the Definition, offering key metrics and insights into the data's structure, compliance, activity, and history. Curiosity will continue to add more widgets over the coming months.
The Data Insights are configured on the Database Connection, these Insights then inform what is shown on the Dashboard. Each job can be configured to run on a schedule, manually, or triggered after a new scan of the database.
Once these insight jobs have run, navigate to your definition and click on Insights in the top right, this will take you to the dashboard.
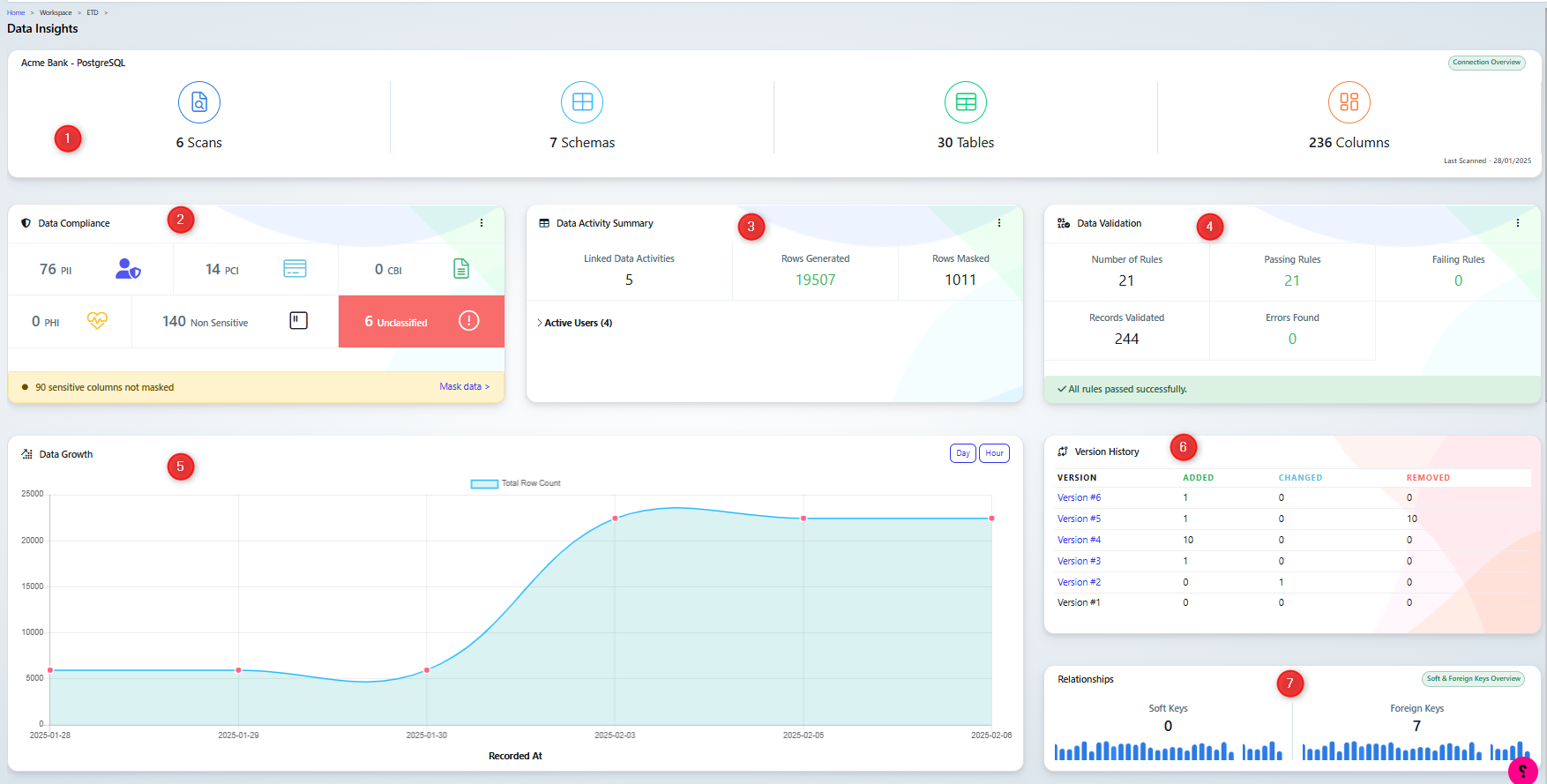
Widgets:
Summary Metrics:
Scans: Total number of scans performed (e.g., 6).
Schemas: Number of schemas in the database (e.g., 7).
Tables: Total number of tables (e.g., 30).
Columns: Total number of columns (e.g., 236).
Data Compliance:
Classification Categories: Breakdown of sensitive data across categories like PII, PCI, PHI, CBI, and unclassified data.
Masking Alert: Indicates the number of sensitive columns not masked (e.g., 90).
Data Activity Summary:
Tracks linked data activities, rows generated, and rows masked.
Data Validation:
Rules and Validation: Displays the number of validation rules applied, the number that passed, and any errors found (e.g., all 21 rules passed successfully).
Data Growth:
A graph showing the total row count over time, with a toggle for daily or hourly intervals.
Version History:
Tracks changes to the database across versions, showing added, changed, and removed elements.
Relationships:
Highlights relationships within the data, including the number of soft keys and foreign keys.
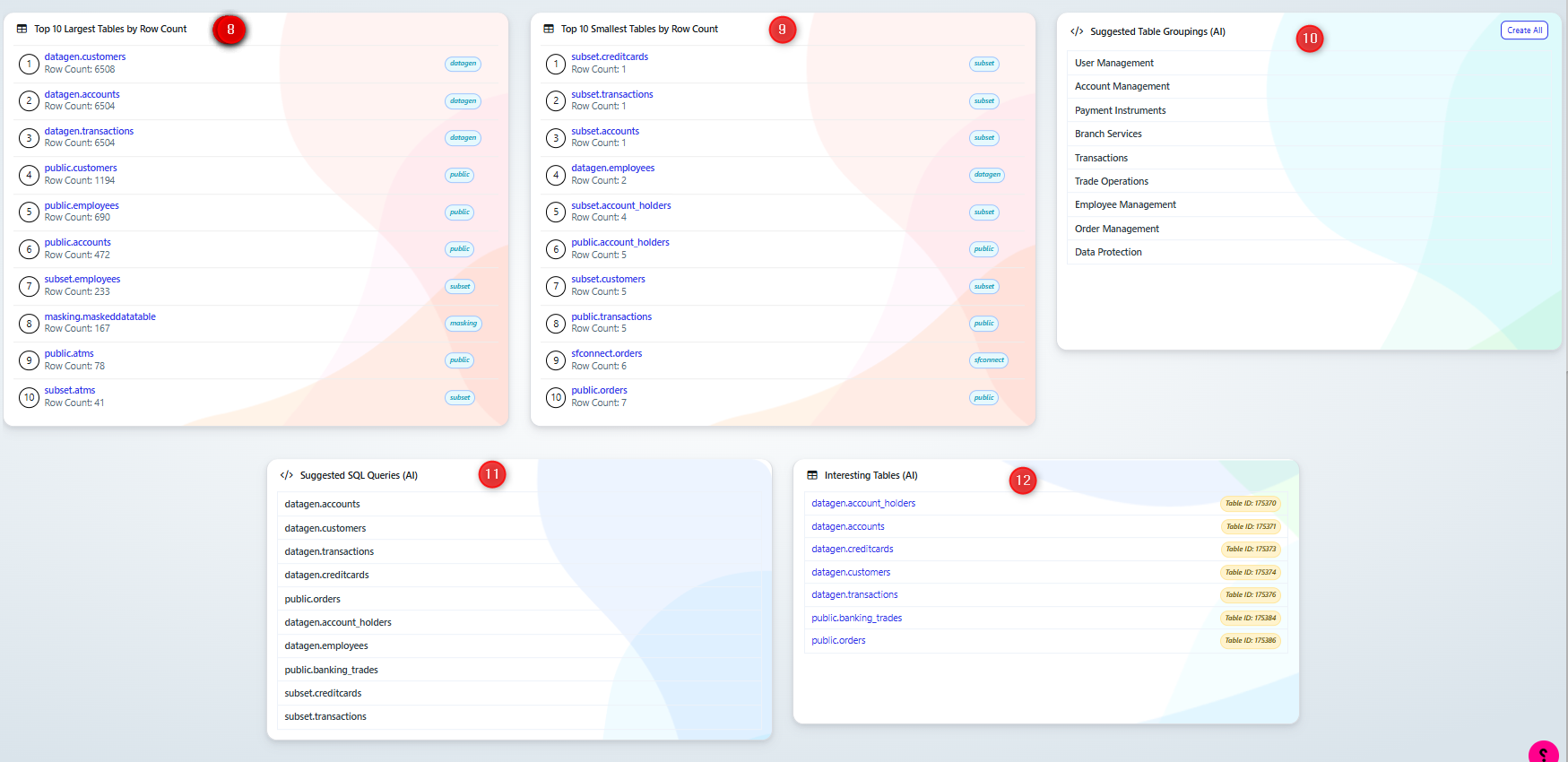
Top 10 Largest Tables by Row Count:
Lists the tables with the highest number of rows, helping users identify data-heavy tables (e.g.,
datagen.customerswith 6508 rows).
Top 10 Smallest Tables by Row Count:
Displays tables with minimal row counts, useful for identifying underutilized or sparse tables (e.g.,
subset.creditcardswith 1 row).
Suggested Table Groupings (AI):
Recommends logical groupings for tables based on their usage or context, such as:
User Management
Account Management
Payment Instruments
Suggested SQL Queries (AI):
Provides recommended SQL queries targeting specific tables, which can streamline common operations or analytics tasks.
Interesting Tables (AI):
Highlights tables of particular interest, with metadata like Table IDs, to guide exploration (e.g.,
datagen.customers,datagen.transactions).
Data analysis for database scan
After scanning a database data analysis statistics are available.
Column Statistics:
Displays detailed information for each column in the selected table or dataset.
Includes metrics like:
Minimum/Maximum: The smallest and largest values in the column.
Sum/Mean/Median/Mode: Aggregated and statistical measures of the data.
Standard Deviation: Variability of the data.
Row Count: Total rows analyzed for the column.
Distinct Count: Unique values within the column.
Null Count: Number of null (empty) values.
Example Insights:
Names Column: Distinct values, count of entries, and no nulls.
Numeric Columns: Ranges (min/max), sums, and variability are highlighted.
Categorical Columns: Unique values (e.g., "Concrete," "Wooden") and counts are displayed.
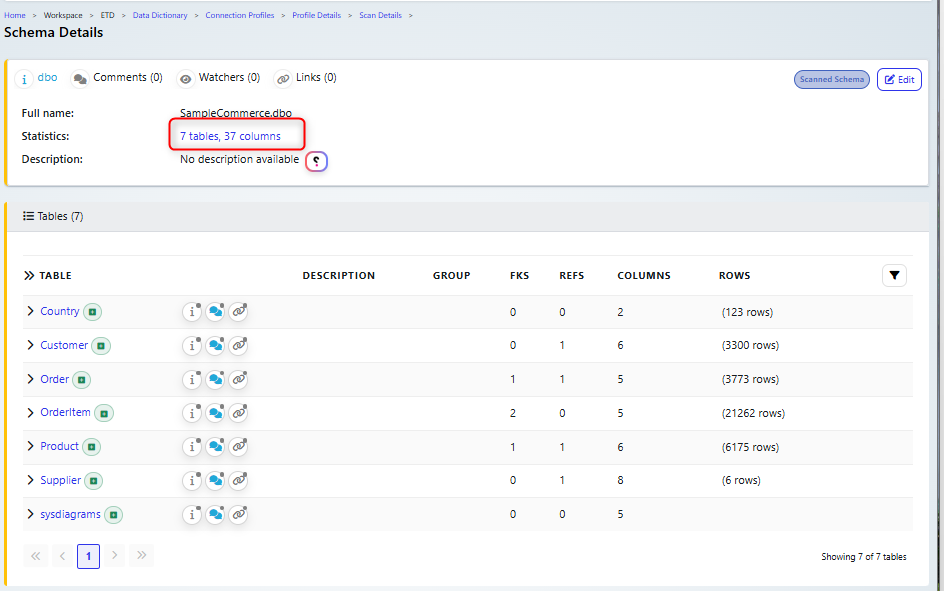
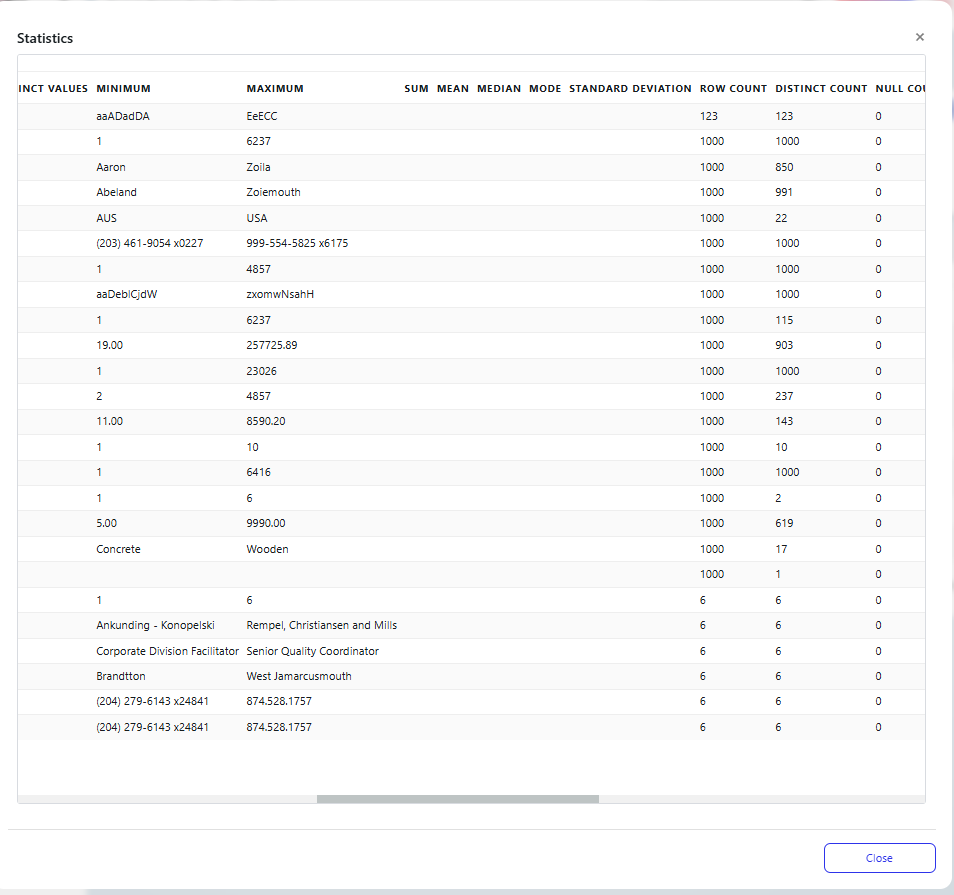
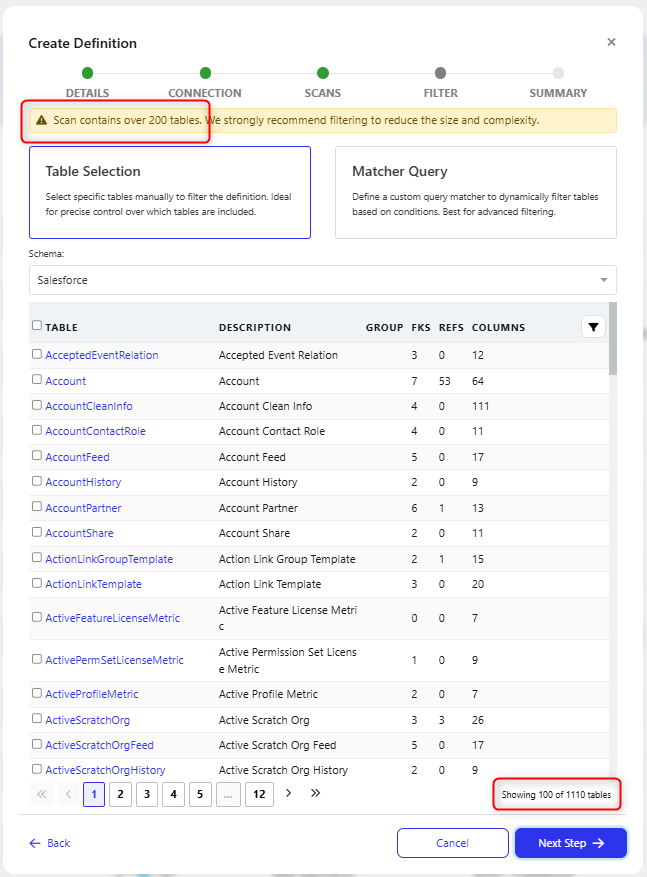
Table filter on database definition connection
When creating a new database definition, there is the option to filter the number of Tables used. This is only required for large databases, over 200 tables.
In the example below there is a database connection with 1110 tables. Here you can select tables manually to use.
Alternatively, you can create a custom Matcher query. Here you can add multiple individual rules or entire rulesets to use.
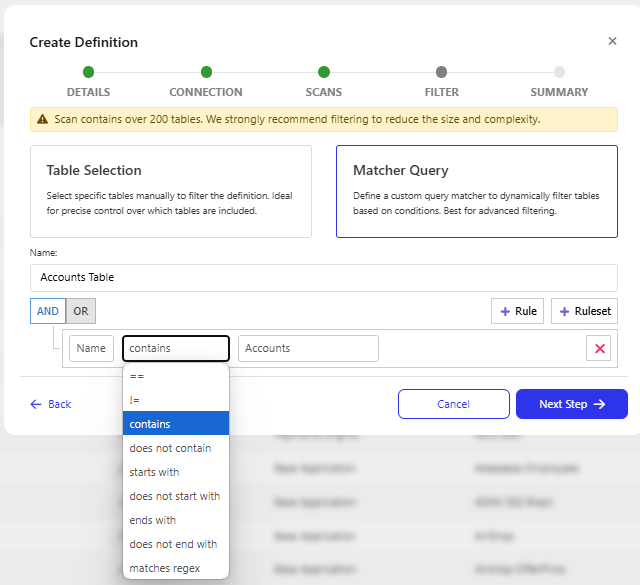
Filtering Options:
Users can set rules to filter table names or other attributes using logical operators:
==(equals)!=(not equals)contains(name includes the specified string)does not contain(excludes tables with specified substrings)starts with(names starting with a particular string)ends with(names ending with a particular string)matches regex(custom pattern matching via regular expressions)
Logical Operators:
AND/OR Logic: Combine multiple rules to create complex filter criteria.
AND: All conditions must be true.
OR: Any condition can be true.
Query composer accelerators
Open query composer directly from database connection. If the connection has been exposed to the query composer, you will see the following option:
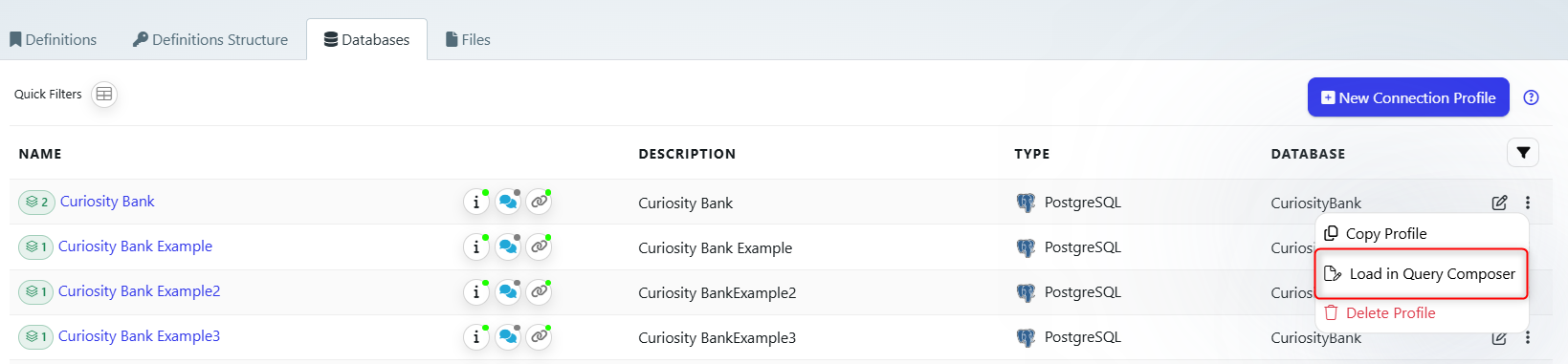
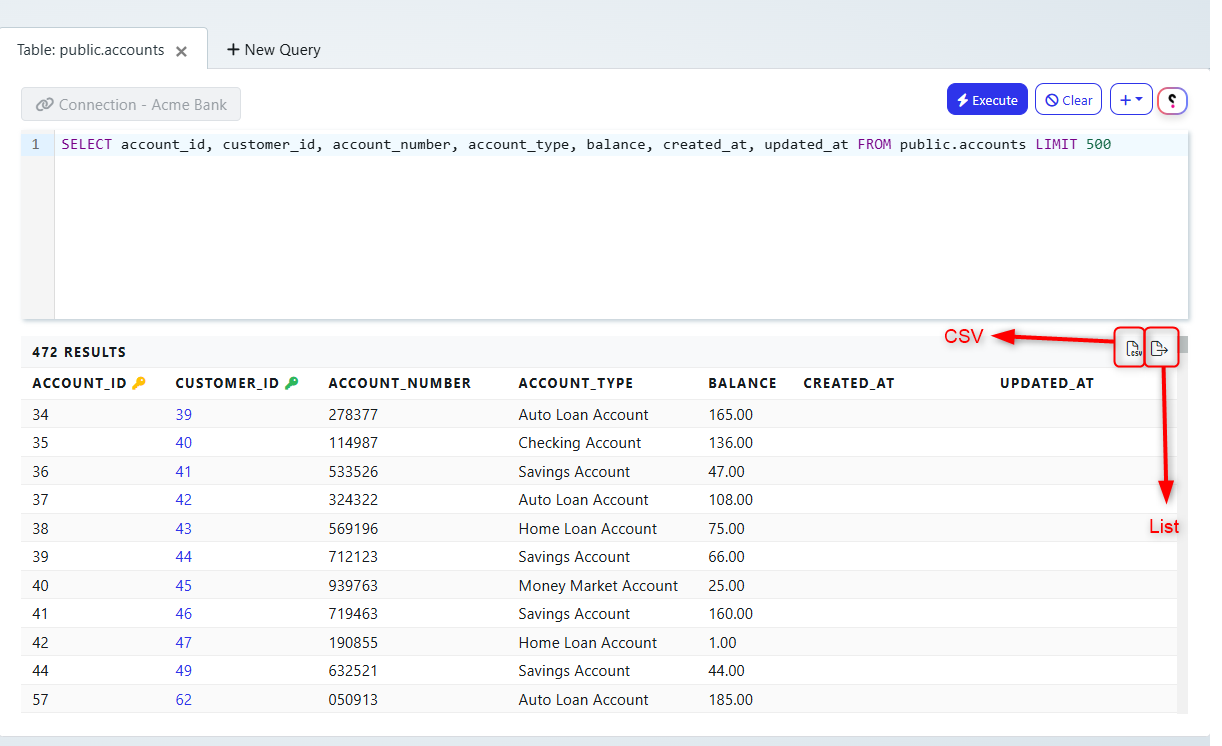
After running a query in the composer, the data that is returned can now be downloaded as a csv or exported to a Data List.
Extra data information on definitions
Additional information has been added to the definitions screen.
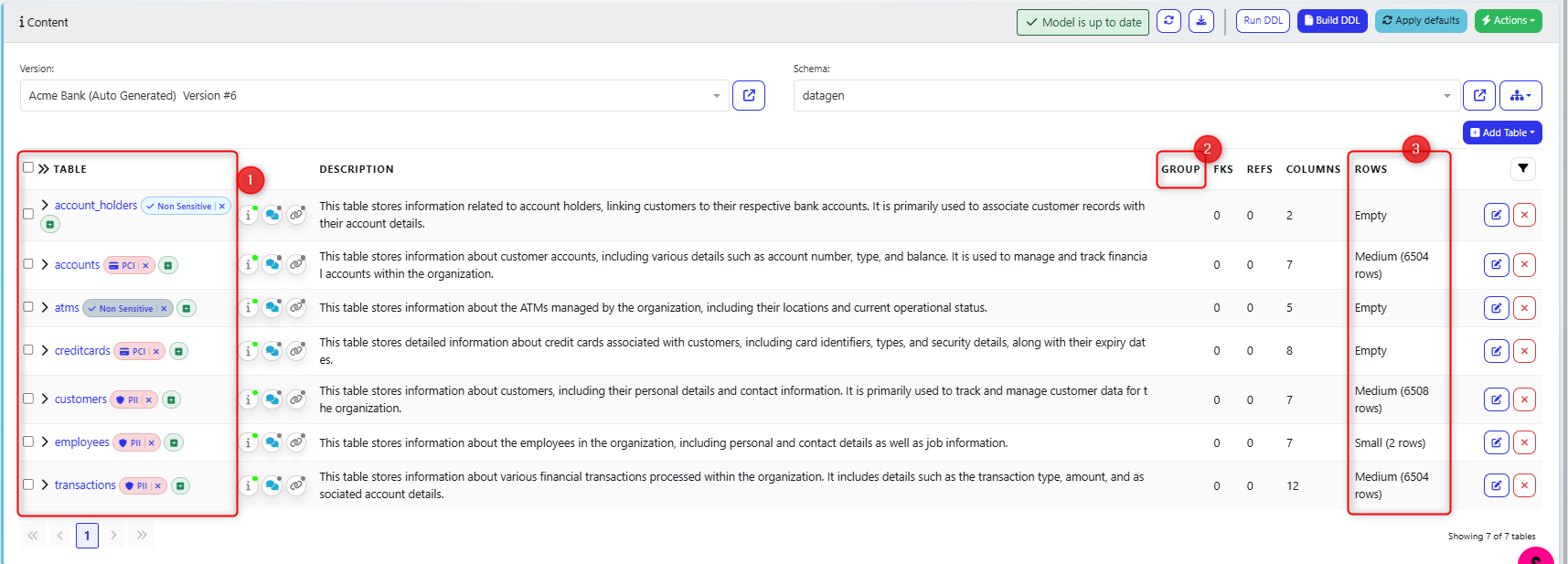
Enhanced tagging options
Table group (if that table is part of a user defined group)
Categorisation of rows (Small - Medium - Large) - this can be defined when scanning the database.
Data painter enhancements for generation rules
There are a series of enhancements to the data painter for data generation rules:
Multi-line expressions are now supported.
Editor for element data gen rules has been added to sequences.
Type casting resolutions.
Users can now run a previews for any functions that refer to a column value.
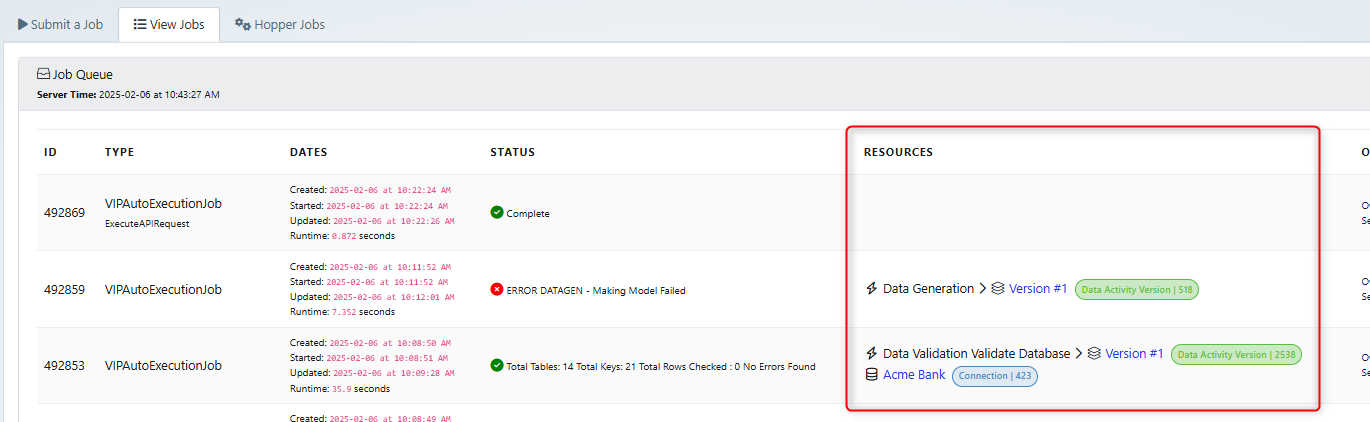
Link to relevant ETD resource in job queue
When opening the job queue to view logs, the relevant ETD resource is now a clickable link.
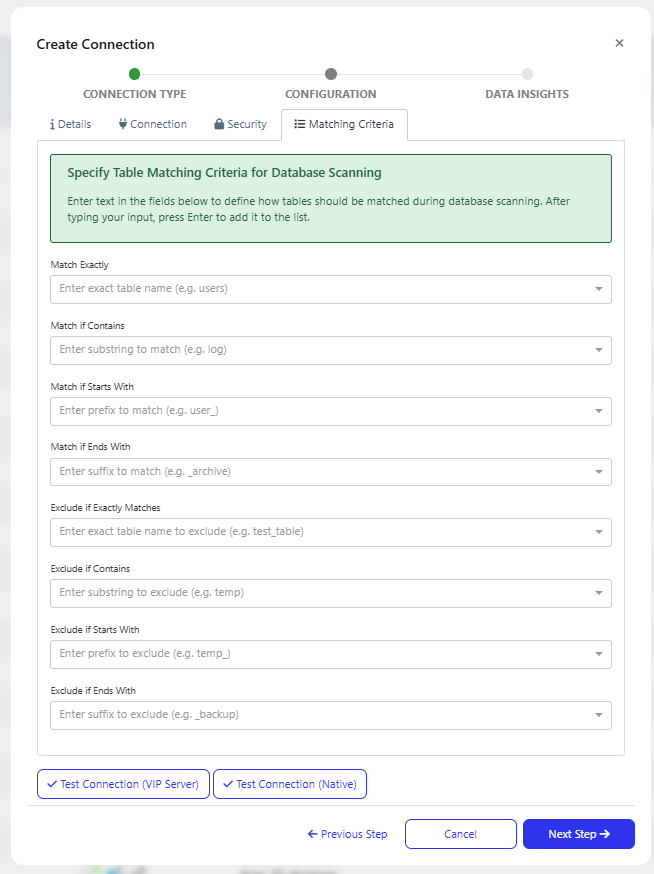
Matching criteria processing on new connection
Advanced matching criteria options have been added for scanning the database when creating a new database connection:
Quality Modeller
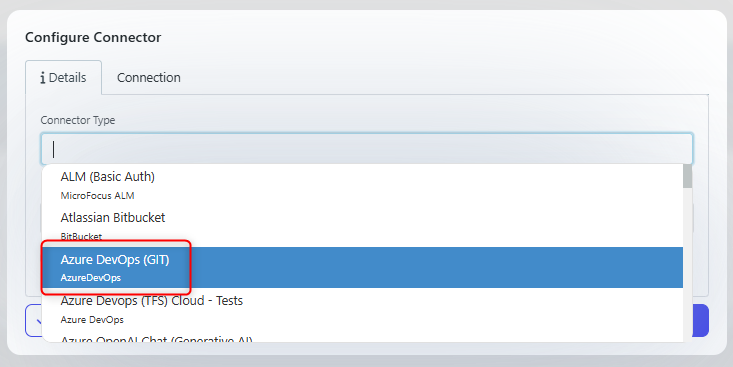
Azure DevOps repositories connector
A dedicated Azure DevOps Repositories connector has been added, this can be found in the connectors dropdown.
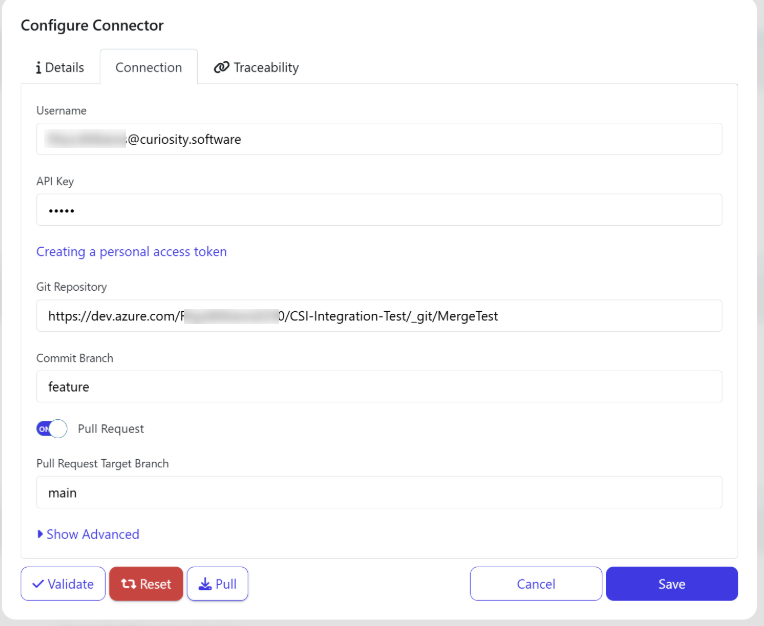
The functionality here is the same as the GitHub, GitLab, and BitBucket connectors. With the ability to configure the repository used, connection details, and the option to configure a pull request.
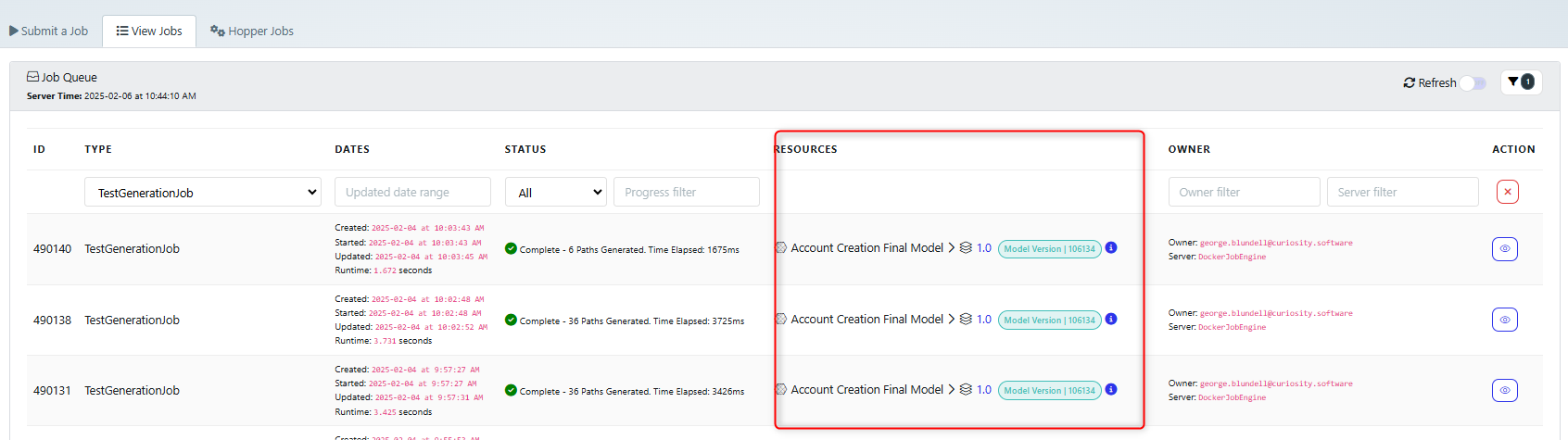
Link to relevant model in job queue
When opening the job queue to view logs, the relevant model related to the job is now a clickable link.
Cosmetic improvements to Data Lists
Column sizing
Filtering
General Platform
AI configuration changes for docker deployments
Before, the AI connection configuration was configured in the ./env file, whereas now there is a custom .yml file with the required environment variables.
Please find the updated instructions here: https://knowledge.curiositysoftware.ie/docs/configure-generative-ai-connection
Windows job engine hosting requires .NET8
For users who host the Docker Job Engine locally on a windows machine, the windows machine now requires .NET8 to be installed. This is an update from .NET6 or .NET5 which were required previously.
Notable bug fixes include:
type casting issues in data generation
subflow variables resolving to FALSE, TRUE, 0 or not at all
Data list cosmetic issues
incorrect tables count in definition
Some columns tagged incorrectly after scan
URL not navigating user to correct place
Models were not shareable without logging in